C’est l’histoire d’une nana… 😊
Après 20 ans de dév pur backend Java, je rencontre Make et je l’adopte pour s’allier avec mes Patterns préférés en FullCode.
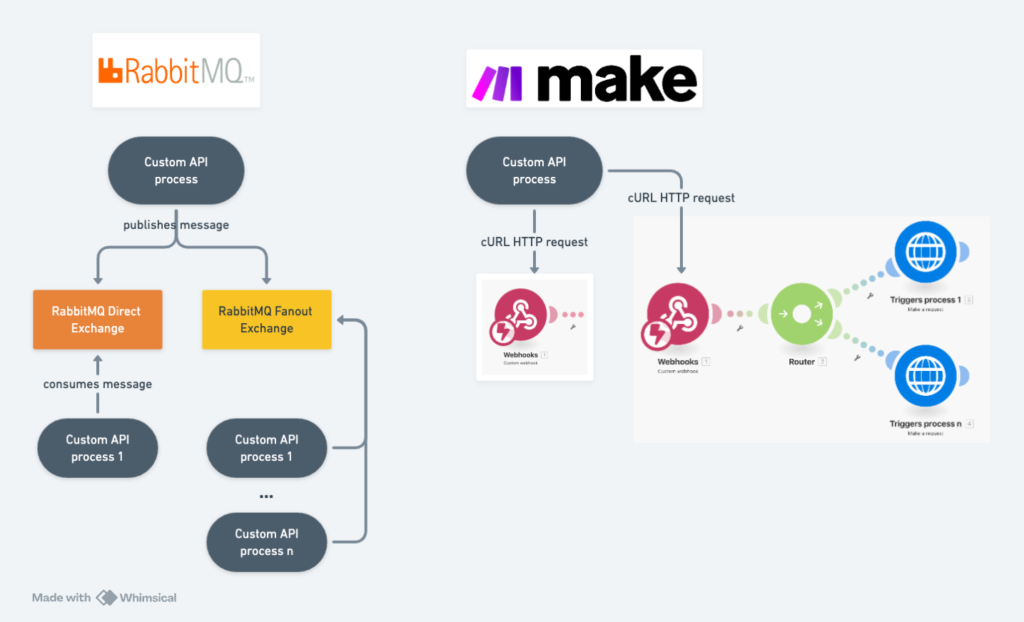
RabbitMQ c’est un logiciel très cool, qui permet de construire des interactions entre services agnostiques les uns des autres, par le système de publication / consommation de messages. Si un service publie un message sur un Direct Exchange, ce message pourra être consommé par un unique autre service. Si le service publie sur un Fanout Exchange, le message pourra être consommé par plusieurs autres services de manières indépendantes. RabbitMQ offre des configurations qui assurent de ne jamais perdre de messages même en cas d’erreurs.
Dans le cadre d’un énorme projet client de construction d’un ERP propriétaire avec beaucoup de dév, je challenge mon architecture pour trouver un moyen d’accélérer les implémentations… 🧠
L’intégration de Make s’impose comme Game Changer ! C’est parti pour le premier POC puis l’implémentation…
Les publications sur un Direct Exchange sont remplacées par un cURL vers un Webhook, point d’entrée d’un scenario.
Les publications sur un Fanout Exchange sont remplacées par un cURL vers un Webhook, suivi d’un Router qui dispatch le payload sur des modules HTTP pour lancer différents scenario.
Bien sûr tous les appels sont sécurisés par Bearer Token, de manière standard.
🏆 Les avantages de cette nouvelle architecture s’imposent immédiatement :
– la documentation de ma nouvelle architecture est quasi-immédiate : l’UI géniale de Make lui donne ce caractère « self-documented » incomparable
– l’accélération de l’implémentation est impressionnante… entre x2 et x3 pour tous les use cases
– la porte est ouverte pour utiliser de manière naturelle et ultra-rapide plein de briques métier spécialisées… pourquoi faudrait-il les recoder ?
– la gestion des erreurs proposée par Make est robuste et me permet de respecter la contrainte « No data loss »
🎈 Alors maintenant, chers Make Product designers, mon voeu le plus cher… avoir une version OnPremise pour pouvoir la déployer sur un cluster Kubernetes dans le Cloud et gagner le pouvoir de l’auto-scaling 🙏
En conclusion de ce Use Case, le NoCode c’est cool… le FullCode + le NoCode c’est sur-puissant en termes de périmètres de fonctionnalités et de rapidité d’implémentation… d’ici peu j’y mets de l’IA entraînée